Tailorable Sampling for Progressive Visual Analytics
IEEE Transactions on Visualization and Computer Graphics (2024)
Authors
Marius Hogräfer Hans-Jörg Schulz
Abstract
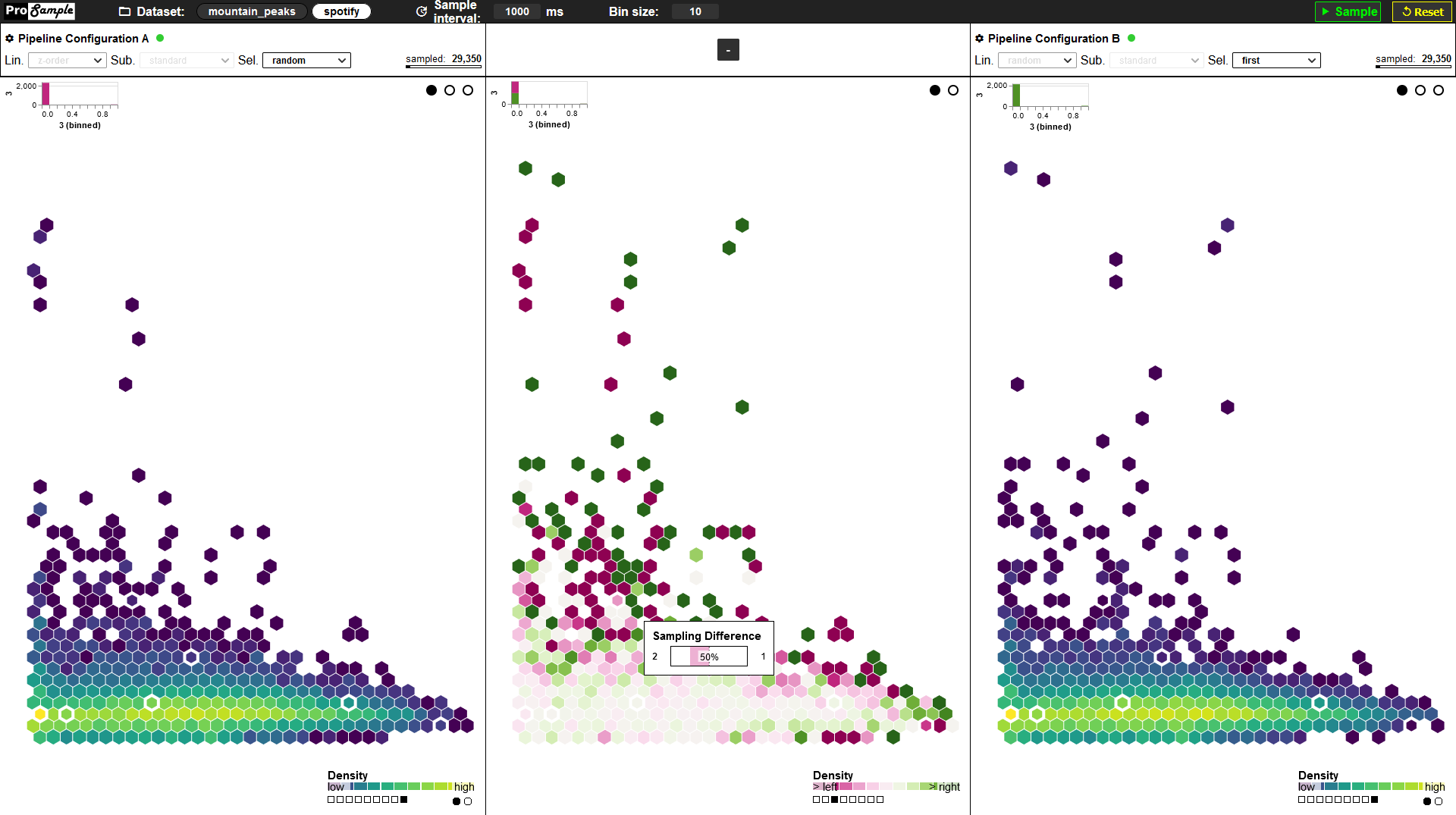
Progressive visual analytics (PVA) allows analysts to maintain their flow during otherwise long-running computations by producing early, incomplete results that refine over time, for example, by running the computation over smaller partitions of the data. These partitions are created using sampling, whose goal it isto draw samples of the dataset such that the progressive visualization becomes as useful as possible as soon as possible. What makes the visualization useful depends on the analysis task and, accordingly, some task-specific sampling methods have been proposed for PVA to address this need. However, as analysts see more and more of their data during the progression, the analysis task at hand often changes, which means that analysts need to restart the computation to switch the sampling method, causing them to lose their analysis flow. This poses a clear limitation to the proposed benefits of PVA. Hence, we propose a pipeline for PVA-sampling that allows tailoring the data partitioning to analysis scenarios by switching out modules in a way that does not require restarting the analysis. To that end, we characterize the problem of PVA-sampling, formalize the pipeline in terms of data structures, discuss on-the-fly tailoring, and present additional examples demonstrating its usefulness.
Citation in BibTeX
To cite this article, we encourage you to use the following bibtex entry in your citation manager:
@article{pva_tailorable_sampling2023,
title = {Tailorable Sampling for Progressive Visual Analytics},
author = {Hogr\"afer, Marius and Schulz, Hans-J\"org},
year = {2023},
journal = {IEEE Transactions on Visualization and Computer Graphics},
volume = {},
number = {},
pages = {},
doi = {10.1109/TVCG.2023.3278084},
url = {https://vis-au.github.io/prosample}
}